Performance & Optimization 4분 읽기
TypeORM Gzip을 활용한 데이터 압축 및 최적화
목차

사내 프로젝트에서 구글 빅쿼리 데이터를 조회하고 특정 시점의 스냅샷을 저장해야 하는 요구사항이 있었습니다. 처음엔 MySQL을 선택했지만 향후 S3 연동도 고려하고 있습니다.
배경 및 문제점
기존 방식
- MySQL의 JSON 타입 컬럼으로 데이터를 저장했습니다.
- 다수의 부동소수점(float) 값이 포함된 JSON 데이터에서 부동소수점 오차로 인한 데이터 불일치가 발생했습니다.
- 이 문제는 TDD를 통해 조기에 발견되었습니다.
해결 방안
- 데이터 일관성을 위해 JSON 데이터를 문자열로 변환하고, MySQL 컬럼 타입을 longtext로 변경했습니다.
새로운 문제점
- 빅쿼리에서 조회한 테이블 중 하나가 약 66MB 크기로, MySQL의 max_allowed_packet(64MB) 한계를 초과하여 에러가 발생했습니다.
- 단순한 설정 조정(max_allowed_packet 증가)은 근본적인 해결책이 아닙니다.
데이터 압축을 통한 최적화
무손실 압축 방식인 gzip을 활용하여 데이터를 효율적으로 압축했습니다.
gzip 선택 이유
- 데이터 정밀도 및 일관성을 유지하는 무손실 압축
- Node.js의 zlib 라이브러리를 활용한 쉬운 구현
- 네트워크 전송과 저장 효율성이 뛰어나 외부 스토리지 연동에도 적합
구현 방식
TypeORM의 transformer를 사용하여 데이터 저장 시 자동 압축하고 조회 시 자동 복원하도록 했습니다.
Transformer 주의사항: TypeORM의 transformer는 동기 함수로 정의해야 하며, 비동기일 경우 예기치 않은 오류가 발생합니다 (관련 GitHub 이슈).
엔티티 구현 예시
@Entity()
export class BigqueryResult extends BaseEntity {
@Column({
type: 'longtext',
transformer: CompressionTransformer,
comment: '쿼리 결과 데이터',
})
public readonly resultData!: string;
}
Transformer 코드
import { gunzipSync, gzipSync } from 'zlib';
export const CompressionTransformer = {
to: (value: string) => {
if (!value) return value;
return gzipSync(Buffer.from(value, 'utf-8')).toString('base64');
},
from: (value: string) => {
if (!value) return value;
return gunzipSync(Buffer.from(value, 'base64')).toString('utf-8');
},
};
테스트 코드
문자열, JSON 객체, 배열, 부동소수점, 다양한 날짜 형식 및 다국어 데이터를 포함한 압축 및 복원 테스트를 수행했습니다.
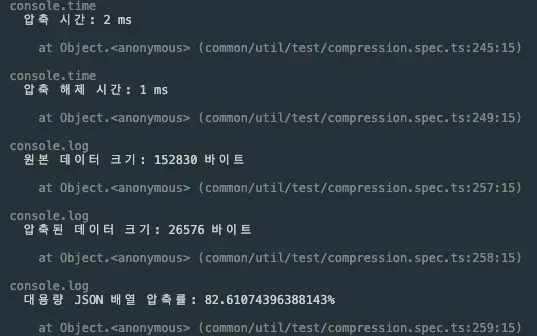
- 압축 시간: 2 ms
- 압축 해제 시간: 1 ms
- 대용량 JSON 배열 압축률: 약 82.61%
실제 빅쿼리 데이터 테스트 결과
- 압축 시간: 339 ms
- 압축 해제 시간: 115 ms
- 원본 크기: 66MB → 압축 후: 1MB (압축률 약 97.46%)
Apple M2 Max 32GB 사내 노트북 기준으로 측정한 결과이며, 서버 환경에서는 차이가 있을 수 있습니다.
결론
- JSON 문자열 변환으로 부동소수점 오차를 해결했으나, 데이터 크기 문제를 유발했습니다.
- gzip 무손실 압축을 도입하여 데이터 크기를 획기적으로 줄이고 네트워크 전송 및 저장 효율성을 높였습니다.
- 설정 조정보다 압축 도입이 더 근본적인 해결책이며, 향후 S3 등 외부 스토리지 연동 시에도 매우 효과적입니다.